Sistemas operativos
Tipos
de sistemas operativos
Los sistemas operativos se
pueden clasificar de diferentes maneras, sistemas operativos de texto, sistemas
operativos gráficos y sistemas operativos que podríamos definir como simples,
que son los que usan aparatos como los refrigeradores y lavadoras actuales, que
a su vez se dividen, por el tipo de estructura, las funcionalidades que poseen,
por el hecho de ser libres, o comerciales o de licencia, y por la versión o
distribución a la que pertenecen.
·
Sistemas
operativos tipo texto.- Los sistemas operativos de tipo texto son
de los primero sistemas operativos que se podían adquirir para uso de máquinas
personales, usan una interfaz de consola para que el usuario pueda realizar
operaciones. Este tipo de sistemas operativos se siguen usando, en aparatos en
los que se necesitan realizar operaciones relativamente simples, como
refrigeradores, lavadoras, hornos, etc., ejemplo de ellos son las versiones
antiguas de MS2, pero también existen varios sistemas operativos actuales que
son de este tipo, como el Unix, y algunas versiones de Linux.
·
Sistemas
operativos gráficos.-En la actualidad la mayoría de los sistemas
operativos de computadoras, son gráficos, es decir, presentan un entorno
gráfico, con el cual hacen más fácil el acceso y uso de estos aparatos a
quienes no tienen un conocimiento profundo de la informática.
·
Sistemas
operativos simples.- Los sistemas operativos básicos o simples, se
pueden encontrar en aparatos como los antes mencionados (refrigeradores, hornos
y lavadoras), ya que sus funciones no necesitan de una elaborada y complicada
red de especificaciones, siendo muy simples en cuanto a los tipos y cantidades
de comandos que deben realizar.
·
Sistemas
operativos de licencia.- En esta categoría entran los sistemas
operativos de tipo Windows de Microsoft, desde sus primeras versiones y
distribuciones hasta las más recientes. Win 3.0, Win 3.1, Win NT, Win 95, Win
98, Win 2000, Windows Me, Windows XP, (y sus varias distribuciones), Windows
Vista, Windows 7, Windows 8, y las diferentes distribuciones que han salido al
mercado de estos sistemas operativos de Microsoft. De la misma manera los
sistemas operativos de Macintosh, Mac OS, y sus varias versiones y variantes
“sistema 1” sistema 1.1, sitema2, sistema 3, sistema 3.2, sistema 3.3, (a
partir del sistema 7.6, se le denominó Mac O S7.6 y a partir de Mac Os9.1, se
le designó a las nuevas versiones Mac OS X, se les conoce con nombres de
felinos, como tiger, lion, o leopard, etc.
·
Sistemas
operativos Libres.- Son aquellos que tienen abierto el código
fuente, es decir, permiten al usuario algunas libertades como mejorarlo,
adaptarlo a las necesidades y liberar esas mejoras al público, así como
ejecutarlo con cualquier propósito lícito. La única restricción que suele haber
en este software es el llamado copyleft, es decir, que quien distribuya con o
sin cambios el sistema, debe permitir las mismas libertades luego de sus
modificaciones, en caso de haberlas, permitiendo que otros usuarios modifiquen
si les parece el sistema parcial o totalmente. Un ejemplo de sistema operativo
libre es Linux y sus muy variadas versiones.
Ejemplos:
·
Windows XP
·
Windows 98
·
Ubuntu
·
Mac OSx Lion
·
Slackware Linux

Memorias RAM
Una memoria RAM o de acceso
aleatorio se utiliza frecuentemente en informática para el almacenamiento de programas
y datos informativos.
La sigla RAM en inglés
significa “Random Access Memory” y se traduce como “Memoria de Acceso
Aleatorio” o, en algunos casos, “Directo”. Una memoria de este tipo es una
pieza que se compone de uno o más chips y que forma parte del sistema de un
ordenador o computadora.
La característica diferencial
de este tipo de memoria es que se trata de una memoria volátil, es decir, que
pierde sus datos cuando deja de recibir energía. Típicamente, cuando el
ordenador es apagado. Así, se distingue de otras memorias, como la ROM, que
tiene la propiedad de almacenar información independientemente de las
condiciones de energía disponibles.
La memoria RAM puede ser del
tipo DDR, DDR2, DDR3 o RDRAM, las cuales se diferencias por la velocidad que
éstas pueden alcanzar, y su rendimiento en diversas condiciones.
Memoria DDR SDRAM
Fue una de las memorias más
utilizadas anteriormente, sin lugar a dudas, la cual se caracteriza por estar
sincronizada y funcionar enviando los datos por duplicado en cada ciclo de
reloj.
Esto permite que la memoria
obtenga el doble de velocidad de procesamiento que el propio bus del sistema,
ofreciendo un rendimiento adecuado del equipo.
Memorias DDR2
Las memorias del tipo DDR2 son
en realidad un avance en la tecnología de las memorias DDR, que gracias a una
serie de cambios estructurales han permitido aumentar la performance del
componente.
Se trata de un módulo DIMM que
dispone de 240 contactos, que se caracteriza por alcanzar una velocidad
duplicada de las frecuencias, en comparación con las del tipo DDR,
posibilitando de esta manera la realización de cuatro transferencias por cada
ciclo de reloj, al contrario de las DDR que sólo permiten hasta dos
transferencias.
Memorias DDR3
En estas se ha incorporado un
sistema que les permite ofrecer un considerable rendimiento con un escaso nivel
de voltaje, ofreciendo así la posibilidad de reducir drásticamente el consumo
de energía.
Si bien las memorias DDR3 son
módulos del tipo DIMM con 240 pines, al igual que las DDR2, lo cierto es que
ambas son incompatibles, por lo que las motherboard más modernas y sofisticadas
incorporan zócalos especiales para memorias DDR3.
Memorias Rambus DRAM
Conocidas también como RDRAM,
las cuales funcionan bajo un protocolo propietario desarrollado por la compañía
Rambus.
Debido a sus elevados costos,
el mercado de usuarios comunes no suelen utilizar este tipo de memoria, por lo
que ha ganado mayor popularidad la del tipo DDR.
En la actualidad las memorias
RDRAM son por lo general utilizadas en grandes servidores y viene incorporada a
la famosa consola de videojuegos PlayStation 3.
Se trata de un módulo del tipo
RIMM, que dispone de 184 contactos, y funciona de manera totalmente diferente a
las memorias convencionales DDR, ya que trabaja elevando las frecuencias de los
chips, para de esta manera evitar los cuellos de botella que pueden reducir la
velocidad de transferencia de datos, alcanzando así un mayor rango de
rendimiento.
Ejemplos:
·
DRAM (Dynamic RAM)
·
VRAM (Vídeo RAM)
·
SRAM (Static RAM)
·
FPM (Fast Page Mode)
·
EDO (Extended Data Output)
·
BEDO (Burst EDO)
·
SDRAM (Synchronous DRAM)
·
DDR SDRAM ó SDRAM II (Double
Data Rate SDRAM)
·
PB SRAM (Pipeline Burst SRAM)
·
RAMBUS
·
ENCAPSULADOS
·
SIMM (Single In line Memory
Module)
·
DIMM (Dual In line Memory
Module)
·
DIP (Dual In line Package)
·
Memoria Caché ó RAM Caché
·
RAM Disk

Internet
Internet es una red de redes
que permite la interconexión descentralizada de computadoras a través de un
conjunto de protocolos denominado TCP/IP. Tuvo sus orígenes en 1969, cuando una
agencia del Departamento de Defensa de los Estados Unidos comenzó a buscar
alternativas ante una eventual guerra atómica que pudiera incomunicar a las
personas. Tres años más tarde se realizó la primera demostración pública del
sistema ideado, gracias a que tres universidades de California y una de Utah
lograron establecer una conexión conocida como ARPANET (Advanced Research
Projects Agency Network).
El desarrollo de Internet ha
superado ampliamente cualquier previsión y constituyó una verdadera revolución
en la sociedad moderna. El sistema se transformó en un pilar de las
comunicaciones, el entretenimiento y el comercio en todos los rincones del
planeta.
Las estadísticas indican que,
en 2006, los usuarios de Internet (conocidos como internautas) superaron los
1.100 millones de personas. Se espera que en la próxima década esa cifra se
duplique, impulsada por la masificación de los accesos de alta velocidad (banda
ancha).
Ejemplos:
·
www.google.com
·
www.search.yahoo.com
·
www.bing.com
·
www.foofoind.com
·
www.rtbot.net
·
www.chacha.com
·
www.duckduckgo.com
·
www.hispavista.com
·
www.baidu.com
·
www.dmoz.com

Intranet
Una intranet es una red
informática que utiliza la tecnología del Protocolo de Internet para compartir
información, sistemas operativos o servicios de computación dentro de una organización.
Este término se utiliza en contraste con Extranet, una red entre las
organizaciones, y en su lugar se refiere a una red dentro de una organización.
A veces, el término se refiere únicamente a la organización interna del sitio
web, pero puede ser una parte más extensa de la infraestructura de tecnología
de la información de la organización, y puede estar compuesta de varias redes
de área local. El objetivo es organizar el escritorio de cada individuo con
mínimo costo, tiempo y esfuerzo para ser más productivo, rentable, oportuno,
seguro y competitivo.
Una Intranet es una red de
ordenadores privada basada en los estándares de Internet.
Las Intranets utilizan
tecnologías de Internet para enlazar los recursos informativos de una
organización, desde documentos de texto a documentos multimedia, desde bases de
datos legales a sistemas de gestión de documentos. Las Intranets pueden incluir
sistemas de seguridad para la red, tablones de anuncios y motores de búsqueda.
Una Intranet puede extenderse
a través de Internet. Esto se hace generalmente usando una red privada virtual
(VPN).
Ejemplos:
·
entidad bancaria
·
movistar
·
ESPE
·
IESS

Lenguajes de programación
Un lenguaje de programación es
un lenguaje formal diseñado para expresar procesos que pueden ser llevados a
cabo por máquinas como las computadoras.
Pueden usarse para crear
programas que controlen el comportamiento físico y lógico de una máquina, para
expresar algoritmos con precisión, o como modo de comunicación humana.
Está formado por un conjunto
de símbolos y reglas sintácticas y semánticas que definen su estructura y el
significado de sus elementos y expresiones. Al proceso por el cual se escribe,
se prueba, se depura, se compila (de ser necesario) y se mantiene el código
fuente de un programa informático se le llama programación.
El ordenador sólo entiende un
lenguaje conocido como código binario o código máquina, consistente en ceros y
unos. Es decir, sólo utiliza 0 y 1 para codificar cualquier acción.
Los lenguajes más próximos a
la arquitectura hardware se denominan lenguajes de bajo nivel y los que se
encuentran más cercanos a los programadores y usuarios se denominan lenguajes
de alto nivel.
Lenguajes de bajo nivel
Son lenguajes totalmente
dependientes de la máquina, es decir que el programa que se realiza con este
tipo de lenguajes no se puede migrar o utilizar en otras máquinas.
Al estar prácticamente
diseñados a medida del hardware, aprovechan al máximo las características del
mismo.
Dentro de este grupo se encuentran:
El lenguaje maquina: este
lenguaje ordena a la máquina las operaciones fundamentales para su
funcionamiento. Consiste en la combinación de 0's y 1's para formar las ordenes
entendibles por el hardware de la máquina.
Este lenguaje es mucho más
rápido que los lenguajes de alto nivel.
La desventaja es que son
bastantes difíciles de manejar y usar, además de tener códigos fuente enormes
donde encontrar un fallo es casi imposible.
El lenguaje ensamblador es un
derivado del lenguaje máquina y está formado por abreviaturas de letras y
números llamadas mnemotécnicos. Con la aparición de este lenguaje se crearon
los programas traductores para poder pasar los programas escritos en lenguaje
ensamblador a lenguaje máquina. Como ventaja con respecto al código máquina es
que los códigos fuentes eran más cortos y los programas creados ocupaban menos
memoria. Las desventajas de este lenguaje siguen siendo prácticamente las
mismas que las del lenguaje ensamblador, ñadiendo la dificultad de tener que
aprender un nuevo lenguaje difícil de probar y mantener.
Lenguajes de alto nivel
Son aquellos que se encuentran
más cercanos al lenguaje natural que al lenguaje máquina.
Están dirigidos a solucionar
problemas mediante el uso de EDD's.
Nota: EDD's son las
abreviaturas de Estructuras Dinámicas de Datos, algo muy utilizado en todos los
lenguajes de programación. Son estructuras que pueden cambiar de tamaño durante
la ejecución del programa. Nos permiten crear estructuras de datos que se
adapten a las necesidades reales de un programa.
Se tratan de lenguajes
independientes de la arquitectura del ordenador. Por lo que, en principio, un
programa escrito en un lenguaje de alto nivel, lo puedes migrar de una máquina
a otra sin ningún tipo de problema.
Estos lenguajes permiten al
programador olvidarse por completo del funcionamiento interno de la maquina/s
para la que están diseñando el programa. Tan solo necesitan un traductor que
entiendan el código fuente como las características de la máquina.
Suelen usar tipos de datos
para la programación y hay lenguajes de propósito general (cualquier tipo de
aplicación) y de propósito específico (como FORTRAN para trabajos científicos).
Lenguajes
de Medio nivel
Se trata de un término no
aceptado por todos, pero q seguramente habrás oído. Estos lenguajes se
encuentran en un punto medio entre los dos anteriores. Dentro de estos
lenguajes podría situarse C ya que puede acceder a los registros del sistema,
trabajar con direcciones de memoria, todas ellas características de lenguajes
de bajo nivel y a la vez realizar operaciones de alto nivel.
Generaciones
La evolución de los lenguajes
de programación se puede dividir en 5 etapas o generaciones.
Primera generación: lenguaje máquina.
Segunda generación: se crearon los primeros
lenguajes ensambladores.
Tercera generación: se crean los primeros
lenguajes de alto nivel. Ej. C, Pascal, Cobol.
Cuarta generación. Son los
lenguajes capaces de generar código por si solos, son los llamados RAD, con lo
cuales se pueden realizar aplicaciones sin ser un experto en el lenguaje. Aquí
también se encuentran los lenguajes orientados a objetos, haciendo posible la
reutilización d partes del código para otros programas. Ej. Visual, Natural
Adabes.
Quinta generación: aquí se encuentran
los lenguajes orientados a la inteligencia artificial. Estos lenguajes todavía
están poco desarrollados. Ej. LISP.
Ejemplos:
·
Ensamblador
·
Visual Basic
·
Cobol
·
Java
·
C
·
C++
·
C#
·
J#
·
SHELL’s de UNIX
·
Oracle PL/SQL

Base de datos
Se le llama base de datos a
los bancos de información que contienen datos relativos a diversas temáticas y categorizados
de distinta manera, pero que comparten entre sí algún tipo de vínculo o
relación que busca ordenarlos y clasificarlos en conjunto.
Una base de datos o banco de
datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados
sistemáticamente para su posterior uso. En este sentido; una biblioteca puede
considerarse una base de datos compuesta en su mayoría por documentos y textos
impresos en papel e indexados para su consulta. Actualmente, y debido al
desarrollo tecnológico de campos como la informática y la electrónica, la
mayoría de las bases de datos están en formato digital, siendo este un
componente electrónico, y por ende se ha desarrollado y se ofrece un amplio
rango de soluciones al problema del almacenamiento de datos.
Existen programas denominados
sistemas gestores de bases de datos, abreviado DBMS, que permiten almacenar y
posteriormente acceder a los datos de forma rápida y estructurada. Las
propiedades de estos DBMS, así como su utilización y administración, se estudian
dentro del ámbito de la informática.
Las bases de datos pueden
clasificarse de varias maneras, de acuerdo al contexto que se esté manejando,
la utilidad de las mismas o las necesidades que satisfagan.
Según la variabilidad de la base de datos
Bases de datos estáticas
Son bases de datos únicamente
de lectura, utilizadas primordialmente para almacenar datos históricos que
posteriormente se pueden utilizar para estudiar el comportamiento de un
conjunto de datos a través del tiempo, realizar proyecciones, tomar decisiones
y realizar análisis de datos para inteligencia empresarial.
Bases de datos dinámicas
Son bases de datos donde la
información almacenada se modifica con el tiempo, permitiendo operaciones como
actualización, borrado y edición de datos, además de las operaciones
fundamentales de consulta. Un ejemplo, puede ser la base de datos utilizada en
un sistema de información de un supermercado.
Según el contenido
Bases de datos bibliográficas
Sólo contienen un subrogante
(representante) de la fuente primaria, que permite localizarla. Un registro
típico de una base de datos bibliográfica contiene información sobre el autor,
fecha de publicación, editorial, título, edición, de una determinada
publicación, etc. Puede contener un resumen o extracto de la publicación
original, pero nunca el texto completo, porque si no, estaríamos en presencia
de una base de datos a texto completo (o de fuentes primarias —ver más abajo).
Como su nombre lo indica, el contenido son cifras o números. Por ejemplo, una
colección de resultados de análisis de laboratorio, entre otras.
Bases de datos de texto completo
Almacenan las fuentes primarias, como por ejemplo, todo el
contenido de todas las ediciones de una colección de revistas científicas.
Directorios
Un ejemplo son las guías telefónicas en formato
electrónico.
Bases de datos o "bibliotecas" de información química o biológica
Son bases de datos que almacenan diferentes tipos de
información proveniente de la química, las ciencias de la vida o médicas. Se
pueden considerar en varios subtipos:
Las que almacenan secuencias de nucleótidos o proteínas.
Las bases de datos de rutas metabólicas
Bases de datos de estructura, comprende los registros de
datos experimentales sobre estructuras 3D de biomoléculas-
Bases de datos clínicas
Bases de datos bibliográficas (biológicas, químicas,
médicas y de otros campos).

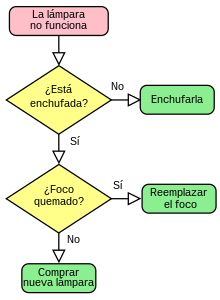
Algoritmo
Un algoritmo es un conjunto
prescrito de instrucciones o reglas bien definidas, ordenadas y finitas que
permite realizar una actividad mediante pasos sucesivos que no generen dudas a
quien deba realizar dicha actividad.2 Dados un estado inicial y una entrada,
siguiendo los pasos sucesivos se llega a un estado final y se obtiene una
solución. Los algoritmos son el objeto de estudio de la algoritmia.1
En la vida cotidiana, se
emplean algoritmos frecuentemente para resolver problemas. Algunos ejemplos son
los manuales de usuario, que muestran algoritmos para usar un aparato, o las
instrucciones que recibe un trabajador por parte de su patrón. Algunos ejemplos
en matemática son el algoritmo de multiplicación, para calcular el producto, el
algoritmo de la división para calcular el cociente de dos números, el algoritmo
de Euclides para obtener el máximo común divisor de dos enteros positivos, o el
método de Gauss para resolver un sistema de ecuaciones lineales.
Los algoritmos pueden ser
expresados de muchas maneras, incluyendo al lenguaje natural, pseudocódigo,
diagramas de flujo y lenguajes de programación entre otros. Las descripciones
en lenguaje natural tienden a ser ambiguas y extensas. El usar pseudocódigo y
diagramas de flujo evita muchas ambigüedades del lenguaje natural. Dichas
expresiones son formas más estructuradas para representar algoritmos; no
obstante, se mantienen independientes de un lenguaje de programación específico.
La
descripción de un algoritmo usualmente se hace en tres niveles:
Descripción de alto nivel. Se establece el problema, se selecciona un modelo matemático y se explica el algoritmo de manera verbal, posiblemente con ilustraciones y omitiendo detalles.
Descripción formal. Se usa pseudocódigo para describir la secuencia de pasos que encuentran la solución.
Implementación. Se muestra el algoritmo expresado en un lenguaje de programación específico o algún objeto capaz de llevar a cabo instrucciones.
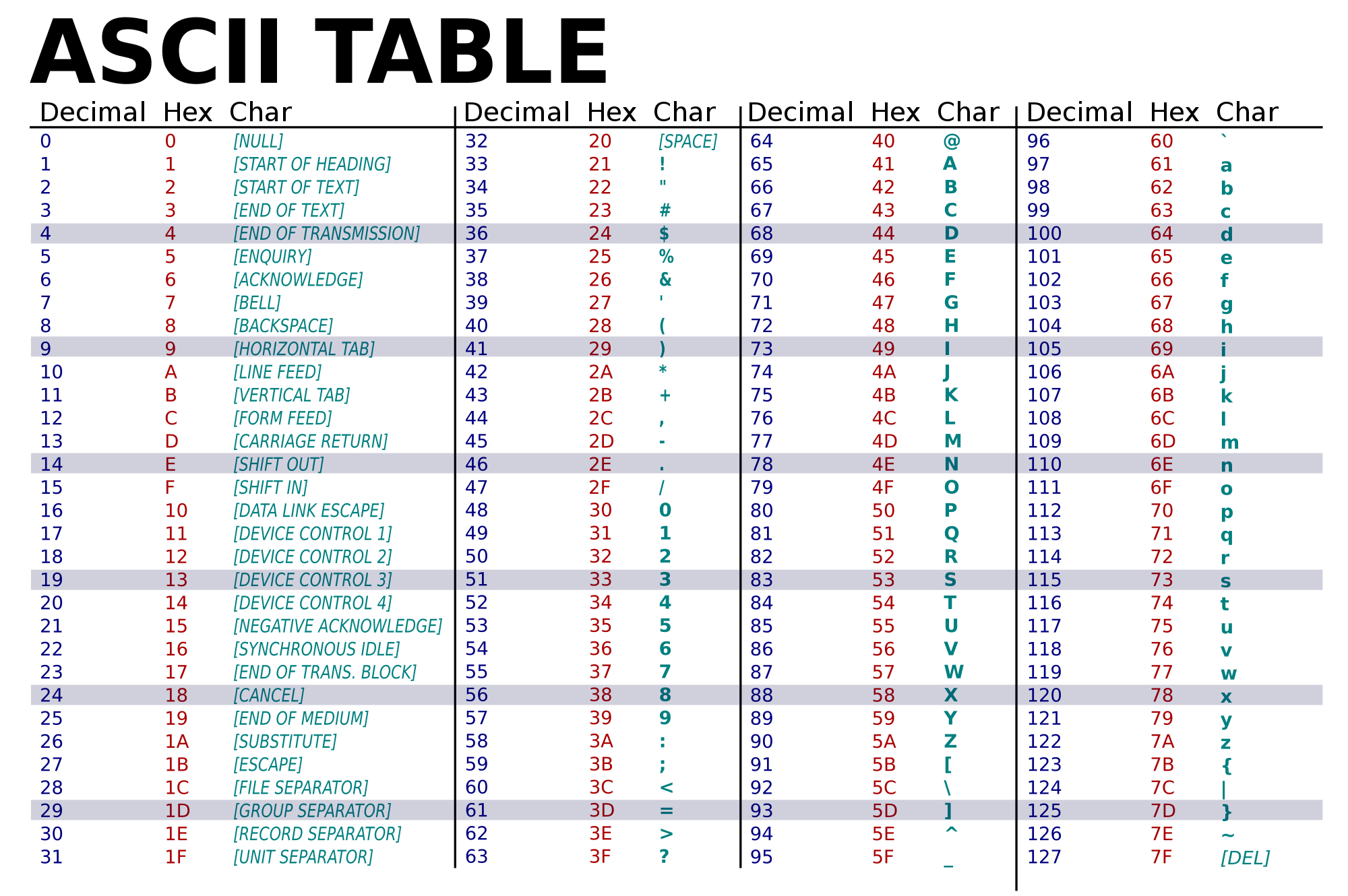
ASCII
ASCII (acrónimo inglés de
American Standard Code for Information Interchange — Código Estándar
Estadounidense para el Intercambio de Información).
Fue creado en 1963 por el
Comité Estadounidense de Estándares (ASA, conocido desde 1969 como el Instituto
Estadounidense de Estándares Nacionales, o ANSI) como una refundición o
evolución de los conjuntos de códigos utilizados entonces en telegrafía. Más
tarde, en 1967, se incluyeron las minúsculas, y se redefinieron algunos códigos
de control para formar el código conocido como US-ASCII.
El código ASCII utiliza 7 bits
para representar los caracteres, aunque inicialmente empleaba un bit adicional
(bit de paridad) que se usaba para detectar errores en la transmisión. A menudo
se llama incorrectamente ASCII a otros códigos de caracteres de 8 bits, como el
estándar ISO-8859-1, que es una extensión que utiliza 8 bits para proporcionar
caracteres adicionales usados en idiomas distintos al inglés, como el español.
ASCII fue publicado como
estándar por primera vez en 1967 y fue actualizado por última vez en 1986. En
la actualidad define códigos para 32 caracteres no imprimibles, de los cuales
la mayoría son caracteres de control que tienen efecto sobre cómo se procesa el
texto, más otros 95 caracteres imprimibles que les siguen en la numeración
(empezando por el carácter espacio).
Casi todos los sistemas
informáticos actuales utilizan el código ASCII o una extensión compatible para
representar textos y para el control de dispositivos que manejan texto como el
teclado. No deben confundirse los códigos ALT+número de teclado con los códigos
ASCII.
Boolean
Es en computación aquel que
puede representar valores de lógica binaria, esto es 2 valores, valores que
normalmente representan falso o verdadero. Se utiliza normalmente en la
programación, estadística, electrónica, matemáticas (Álgebra booleana), etc.
Para generar un dato o valor
lógico a partir de otros tipos de datos, típicamente, se emplean los operadores
relacionales (u operadores de relación), por ejemplo: 0 es igual a falso y 1 es
igual a verdadero
(3>2)= 1 = verdadero
(7>9)= 0 = falso
Una vez se dispone de uno o
varios datos de tipo booleano, estos se pueden combinar en expresiones lógicas
mediante los operadores lógicos (Y, O, NO, …). Un ejemplo de este tipo de
expresiones sería:
Verdadero Y falso → falso
Falso O verdadero → verdadero
NO verdadero → falso

Memoria caché
La caché es la memoria de
acceso rápido de una computadora, que guarda temporalmente los datos recientemente
procesados (información).1
La memoria caché es un búfer
especial de memoria que poseen las computadoras, que funciona de manera similar
a la memoria principal, pero es de menor tamaño y de acceso más rápido. Es
usada por el microprocesador para reducir el tiempo de acceso a datos ubicados
en la memoria principal que se utilizan con más frecuencia.
La caché es una memoria que se
sitúa entre la unidad central de procesamiento (CPU) y la memoria de acceso
aleatorio (RAM) para acelerar el intercambio de datos.
Cuando se accede por primera
vez a un dato, se hace una copia en la caché; los accesos siguientes se
realizan a dicha copia, haciendo que sea menor el tiempo de acceso medio al
dato. Cuando el microprocesador necesita leer o escribir en una ubicación en
memoria principal, primero verifica si una copia de los datos está en la caché;
si es así, el microprocesador de inmediato lee o escribe en la memoria caché,
que es mucho más rápido que de la lectura o la escritura a la memoria
principal.
La unidad caché es un sistema
especial de almacenamiento de alta velocidad. Puede ser tanto un área reservada
de la memoria principal como un dispositivo de almacenamiento de alta velocidad
independiente.
Hay dos tipos de caché
frecuentemente usados en computadoras personales: memoria caché y caché de disco.
Una
memoria caché, a veces llamada “RAM caché”, es una parte de
RAM estática (SRAM) de alta velocidad, más rápida que la RAM dinámica (DRAM)
usada como memoria principal. La memoria caché es efectiva dado que los
programas acceden una y otra vez a los mismos datos o instrucciones. Guardando
esta información en SRAM, la computadora evita acceder a la lenta DRAM.
Cuando se encuentra un dato en
la caché, se dice que se ha producido un acierto, siendo un caché juzgado por
su tasa de aciertos (hit rate). Los sistemas de memoria caché usan una
tecnología conocida por caché inteligente en la cual el sistema puede reconocer
cierto tipo de datos usados frecuentemente. Las estrategias para determinar qué
información debe ser puesta en la caché constituyen uno de los problemas más
interesantes en la ciencia de las computadoras. Algunas memorias caché están
construidas en la arquitectura de los microprocesadores. Por ejemplo, el
microprocesador Pentium II: tiene 32 KiB de caché de primer nivel (level 1 o
L1) repartida en 16 KiB para datos y 16 KiB para instrucciones; la caché de
segundo nivel (level 2 o L2) es de 512 KiB y trabaja a mitad de la frecuencia
del microprocesador. La caché L1 está en el núcleo del microprocesador, y la L2
está en una tarjeta de circuito impreso junto a éste.
La
caché de disco trabaja sobre los mismos principios que la
memoria caché, pero en lugar de usar SRAM de alta velocidad, usa la
convencional memoria principal. Los datos más recientes del disco duro a los
que se ha accedido (así como los sectores adyacentes) se almacenan en un búfer
de memoria. Cuando el programa necesita acceder a datos del disco, lo primero
que comprueba es la caché de disco para ver si los datos ya están ahí. La caché
de disco puede mejorar notablemente el rendimiento de las aplicaciones, dado
que acceder a un byte de datos en RAM puede ser miles de veces más rápido que
acceder a un byte del disco duro.

Código fuente
El código fuente de un
programa informático (o software) es un conjunto de líneas de texto que son las
instrucciones que debe seguir la computadora para ejecutar dicho programa. Por
tanto, en el código fuente de un programa está escrito por completo su
funcionamiento.
El código fuente de un
programa está escrito por un programador en algún lenguaje de programación,
pero en este primer estado no es directamente ejecutable por la computadora,
sino que debe ser traducido a otro lenguaje o código binario; así será más
fácil para la máquina interpretarlo (lenguaje máquina o código objeto que sí
pueda ser ejecutado por el hardware de la computadora). Para esta traducción se
usan los llamados compiladores, ensambladores, intérpretes y otros sistemas de
traducción.
El término código fuente
también se usa para hacer referencia al código fuente de otros elementos del
software, como por ejemplo el código fuente de una página web que está escrito
en lenguaje de marcado HTML o en Javascript, u otros lenguajes de programación
web, y que es posteriormente ejecutado por el navegador web para visualizar dicha
página cuando es visitada.
El área de la informática que
se dedica a la creación de programas, y por tanto a la creación de su código
fuente, es la programación.
Cookie
Una cookie (o galleta
informática) es una pequeña información enviada por un sitio web y almacenado
en el navegador del usuario, de manera que el sitio web puede consultar la
actividad previa del usuario.
Sus
principales funciones son:
Llevar el control de usuarios:
cuando un usuario introduce su nombre de usuario y contraseña, se almacena una
cookie para que no tenga que estar introduciéndolas para cada página del
servidor. Sin embargo, una cookie no identifica a una persona, sino a una
combinación de computador-navegador-usuario.
Conseguir información sobre
los hábitos de navegación del usuario, e intentos de spyware (programas espía),
por parte de agencias de publicidad y otros. Esto puede causar problemas de
privacidad y es una de las razones por la que las cookies tienen sus
detractores.
Originalmente, solo podían ser
almacenadas por petición de un CGI desde el servidor, pero Netscape dio a su
lenguaje Javascript la capacidad de introducirlas directamente desde el
cliente, sin necesidad de CGIs. En un principio, debido a errores del
navegador, esto dio algunos problemas de seguridad. Las cookies pueden ser
borradas, aceptadas o bloqueadas según desee, para esto solo debe configurar
convenientemente el navegador web.

Descomprimir
Descomprimir es el proceso
inverso a comprimir. En general, la información comprimida debe primero
descomprimirse para que pueda ser accedida, leída o modificada.
En general, los archivos
comprimidos pueden descomprimirse con el mismo programa que se usó para
comprimirlos.
Por
ejemplo, los archivos comprimidos .zip ó .rar, pueden
descomprimirse con WinRAR, WinZip o programas similares.

Pseudocódigo
Es una descripción de alto
nivel compacta e informal1 del principio operativo de un programa informático u
otro algoritmo.
Utiliza las convenciones
estructurales de un lenguaje de programación real,2 pero está diseñado para la
lectura humana en lugar de la lectura mediante máquina, y con independencia de
cualquier otro lenguaje de programación. Normalmente, el pseudocódigo omite
detalles que no son esenciales para la comprensión humana del algoritmo, tales
como declaraciones de variables, código específico del sistema y algunas
subrutinas. El lenguaje de programación se complementa, donde sea conveniente,
con descripciones detalladas en lenguaje natural, o con notación matemática
compacta. Se utiliza pseudocódigo pues este es más fácil de entender para las
personas que el código del lenguaje de programación convencional, ya que es una
descripción eficiente y con un entorno independiente de los principios
fundamentales de un algoritmo. Se utiliza comúnmente en los libros de texto y
publicaciones científicas que se documentan varios algoritmos, y también en la
planificación del desarrollo de programas informáticos, para esbozar la
estructura del programa antes de realizar la efectiva codificación.
No existe una sintaxis
estándar para el pseudocódigo, aunque los ocho IDE's que manejan pseudocódigo
tengan su sintaxis propia. Aunque sea parecido, el pseudocódigo no debe
confundirse con los programas esqueleto que incluyen código ficticio, que
pueden ser compilados sin errores. Los diagramas de flujo y UML pueden ser
considerados como una alternativa gráfica al pseudocódigo, aunque sean más
amplios en papel.

No hay comentarios:
Publicar un comentario